基于 Moses 的文言文统计机器翻译系统
Note
这是一份参加学校办的科技竞赛写的论文。既然没得奖,就直接放出来供大家参考吧。本文内容参见之前发布的 《文言文机器翻译》。点击使用 在线演示。
为了更清楚地列出所采用的资源和工具,在发布时另外标注了链接和符号角标。
摘要:本项目制作了一种文言文机器翻译系统,使用了基于词组的统计翻译模型。通过收集整理大量平行语料、训练针对文言文的分词系统并应用统计机器翻译中的先进技术,在控制了模型大小和内存占用的情况下,使本系统的翻译结果质量超过了现有系统的水平。本系统拥有较为友好的用户交互界面,能根据文本特征自动确定翻译方向并在结果中显示原文和译文中词语的对应关系,最终本系统可以为用户提供了一个新的文言文辅助阅读方法。
关键词:文言文,统计机器翻译,自然语言处理
A statistical machine translation system for Classical Chinese based on Moses
Abstract: This project presents a statistical machine translation system that can translate text between Classical and Modern Chinese using phrase-based translation models. By collecting a considerable amount of parallel corpora, training a word segmentation system for Classical Chinese and applying state-of-the-art statistical machine translation technologies, the translation result is better than that of current systems despite the model size and memory constraints. This system has a user-friendly graphical user interface, which can detect translation direction based on the source text and show the relationships between source and target words. This system provides users a new kind of assistant for reading Classical Chinese.
Keywords: Classical Chinese, Statistical Machine Translation, Natural Language Processing
目录
1 概述
文言文是古汉语的书面语言,具有文字简练的特点,与现代白话文有较大区别。要读懂文言文需要有对应的训练并积累一定的阅读量,这导致大多数人较难读懂古代典籍。为了帮助阅读和理解文言文,本项目实现了一种文言文翻译系统。
统计机器翻译是广泛采用的一种机器翻译的模式,其通过对大量平行语料进行分析,构造统计模型,从而使用该模型生成翻译。寻找最佳翻译的过程就是找到根据模型的参数产生概率最高的句子。Moses [1] 是一套成熟完善的统计机器翻译系统,可以训练产生能够翻译任意语言对的翻译模型,并通过高效的搜索算法找到最有可能的翻译结果。
本项目采用基于词组的统计翻译模型 [2],通过收集大量平行语料,并根据文言文和现代汉语的特点进行了相应处理和优化,得到了质量较高的翻译结果。本项目同时设计了一个基于网页的用户交互界面。
2 语料收集与处理
语料的收集处理是统计机器翻译的重要组成部分。由于统计机器翻译的原理和特点,需要有大量平行语料并进行相对应的处理,才能训练得到较好的翻译结果。
2.1 平行语料
本项目使用了大量网络上可获得的平行语料,包括各个文言文翻译网站以及古代书籍的译注版本。对于这些来源,都分别按照其格式特点进行了半自动半人工的处理,从而丰富了平行语料的来源,减少了大量无效数据。根据处理后平行语料的质量和对齐程度不同,可分为极少量的按句对齐、一些按段落对齐和其他大部分按篇章对齐的语料。Moses 统计机器翻译系统主要针对的是按句翻译,也就需要将平行语料按句对齐。
已按句对齐的语料无需处理即可直接使用。按段落对齐和按篇章对齐的处理步骤相似,首先都要将其进行断句处理。断句规则为,在分号、句号、感叹号、问号后断句;如果有下引号,则在其之后断句;在冒号和上引号之间断句。在实际翻译时也必须采用相同的断句规则。之后,采用机器翻译辅助句对齐的方法 [3],使用之前的训练的模型粗略翻译一遍原文,保证原文和机翻译文能按句对齐,以修改后的 BLEU 得分比较机翻译文和参考译文的相似度,最后使原文和参考译文能按句对齐。最后,统一过滤无效句对并去重,得到按句对齐、可供 Moses 直接使用的平行语料,称为训练集,约有八十五万句对;从上述平行语料中另外人工抽取并校对一千对左右翻译质量较高的句子作为调优集和评估集。
2.2 单一语言语料
除了平行语料,单一语言语料的作用在统计机器翻译中也是十分重要的。现代白话文语料除了上述平行语料之外,主要包括新闻 [*]、小说、字幕 [†]和维基媒体项目 [‡] [§] (除中文维基文库)等 [¶]。文言文语料除了平行语料之外,主要包括中文维基文库中筛选出的古代和近代的文献。最终得到的单一语言语料数量较大,约为上述平行语料的二十倍,作为语言模型的训练材料,能更好地保证输出语言的通顺流畅。
| [*] | 可参考 搜狗全网新闻数据,本项目未使用 |
| [†] | Web Inventory of Transcribed and Translated Talks |
| [‡] | 维基媒体项目数据库 |
| [§] | 维基媒体项目导出数据转文本 |
| [¶] | 还有 OPUS: the open parallel corpus,未标注参考文献 |
2.3 文字的选择
本项目对于上述所有语料,统一转换成简化字 [#],即训练的模型使用的文字为简体字。中华人民共和国自 1956 年后施行汉字简化制度,所以在此之前的文献应以传统汉字(繁体字)保存。然而,由于网络上使用繁体中文的平行语料资源严重缺乏;繁体中文语料来源质量参差不齐,有些是使用机器从简体简单转换而来,鱼龙混杂 [♠];校对原文需要极大的人力;而且无法确保能将用户输入的简体中文输入正确转换为对应繁体,正确处理文言文的简繁转换比对白话文的简繁转换更为困难 [♥],所以经过考虑,语料和用户输入将统一转换为简化字之后再进行处理。 [♦]
| [#] | 这里采用 OpenCC |
| [♠] | 指维基文库。 |
| [♥] | 可以尝试再来一份用于简繁转换的统计机器翻译模型。 |
| [♦] | 在线上采用「简易中文简繁转换」 |
3 模型训练
这个翻译系统使用的特征包括短语翻译模型、语言模型、调序模型以及一些稀疏特征。翻译模型(短语翻译表)使源语言和目标语言的词汇能互相对应,语言模型确保输出的是通顺的目标语言,调序模型可以适当改变输入语句的顺序,附加的稀疏特征能给输出评分更多参考,可较大程度提高翻译质量。
3.1 中文分词
在训练翻译模型和语言模型之前,需要先对文言文和白话文进行针对性的分词处理以提高翻译质量。[4] 对于现代白话文,使用了 “结巴”中文分词软件,禁用了默认的隐马尔可夫新词发现模型,防止产生模型外词汇。
对于文言文,不能简单使用白话文的分词模型,所以首先构建了文言文分词所需要使用的词汇表。词汇表来源有“结巴”包含的默认词典(按词性筛选出部分实词),台湾教育部《重编国语词典修订本》(按词汇类别筛选) [♣] 以及各种关于历史人物、地名、朝代、官职等输入法词库 [**],再加上用程序生成的数字、方位、干支等词汇,共计约三万八千条。 [††]
鉴于文言文大部分为单音节词汇,少有分词歧义,所以在训练分词模型时简单采用了首先进行最大正向匹配,再统计每个词汇出现次数的方法,即最大似然估计,最后筛选掉极低频词汇。在文言文分词时,运用此字典即可获得较好的分词效果。
| [♣] | 《萌典》 数据 |
| [**] | 主要是搜狗、百度和 QQ 拼音词库。 |
| [††] | 下载:简体、繁体 |
3.2 语言模型
在训练语言模型时采用上述在数量上更多的单一语言语料。语言模型采用 KenLM 语言模型工具估算生成四元语言模型,其使用 Modified Kneser-Ney 算法 [5] 平滑 n 元组数据。生成 ARPA 文本格式的语言模型之后,转换成 KenLM [6] 的 Trie 数据结构二进制文件。使用这种数据结构的文件相比其实现的另外一种 Probing(散列表)数据结构,文件更小、占用内存更少,但速度稍慢。因为这些语言模型所用的语料更新次数相对较少且模型生成速度慢,所以不在下述“实验管理系统”中生成。
3.3 实验管理系统
通过使用 Moses 附带的“实验管理系统”[7] [‡‡],编写一个配置文件,就可自动完成模型训练的各个过程。训练步骤为:分词、过滤、词对齐、建立翻译及调序模型、过滤模型、权重调优、评估。
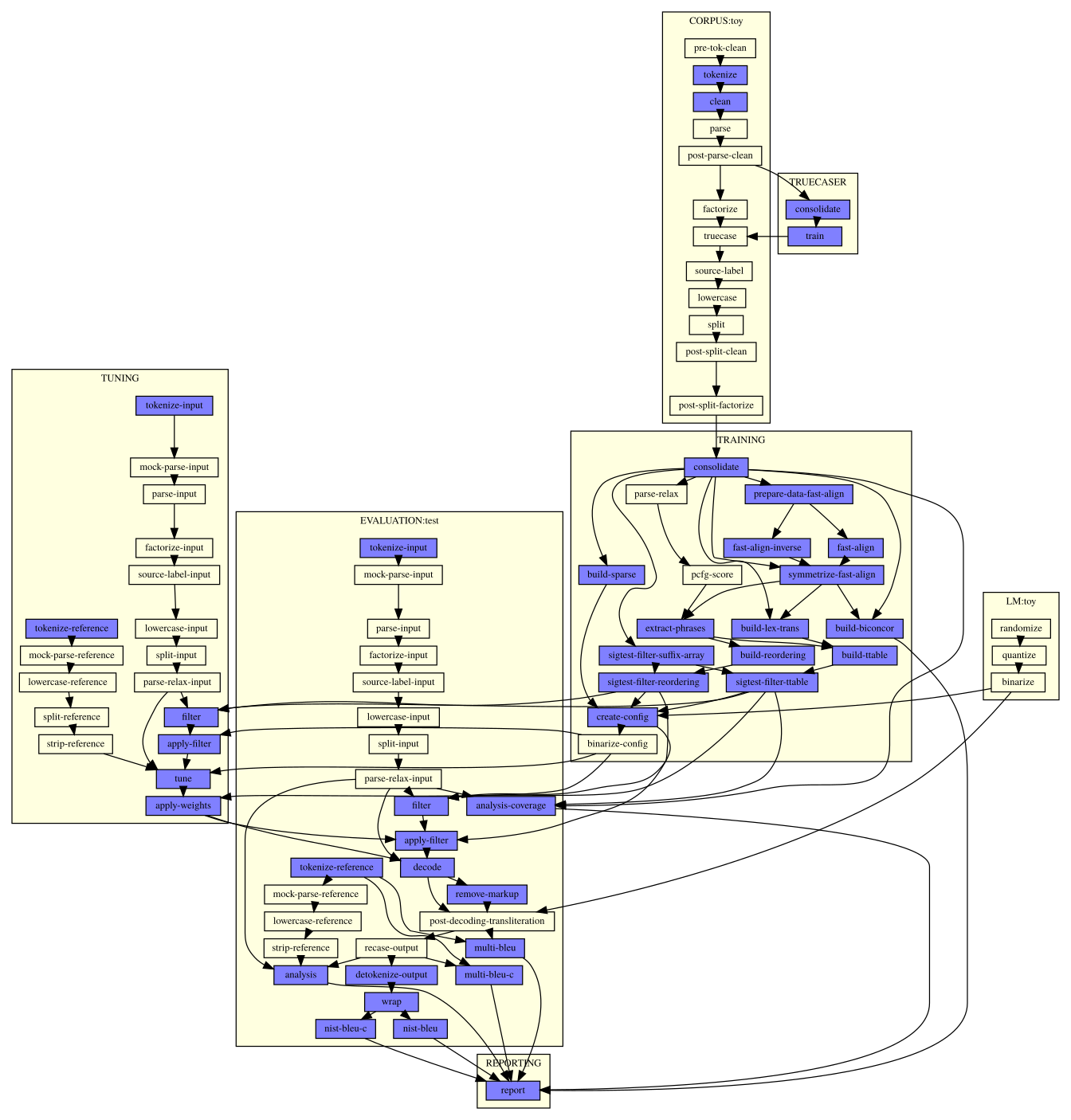
图 1 实验管理系统生成的模型训练步骤
首先系统按照配置,将训练集、调优集和评估集使用上述分词方法进行分词,并筛选掉超过 100 词的句子,因为长句通常可靠性不高,而且会减慢词对齐速度。然后,系统将分词后的平行语料进行预处理,准备进行词对齐。在本项目中,使用基于 IBM Model 2 的 fast_align [8] 工具进行词对齐。该工具比常用的基于 IBM Model 4 的词对齐工具约快十倍,且在源语言和目标语言语序相似的情况下质量相当。
词对齐之后,系统提取词组表,合并预先准备的文言文词典的释义作为附加词组表,限定词组的最大长度为 4,并同时生成词汇调序表。按照对词组在平行语料中共同出现的显著性检验,可以删减掉大部分词组表而不影响、甚至提高翻译得分 [9],从而节省大量空间。同时,使用压缩词汇表和调序表技术 [10] 能进一步减少磁盘占用而不影响翻译速度。
在调优时不仅考虑翻译模型、语言模型等特征,还加入了目标词汇插入、源词汇删除、词汇直接翻译、词汇长度四种稀疏特征,这可以使 BLEU 得分提高约 20%。因为特征数目较多,调优采用 k-best MIRA 算法 [11]。得到最佳特征参数后,对模型进行整体评估,计算 BLEU [12] 评分,从而可以对翻译质量进行量化比较。上述过程所产生的最终模型文件较小 [§§],翻译时内存占用适中 [¶¶],适合在云端服务部署。
因为将文言文和白话对调再训练模型即可获得反向翻译功能,所以每次均进行双向训练,得到文言文到白话文和白话文到文言文两个翻译模型。这两个模型互相独立,因此不能保证它们有相同的翻译质量。
| [‡‡] | Experiment Management System. 此部分涉及内容参见 Moses 文档。 |
| [§§] | 两个模型总计约 0.5G。 |
| [¶¶] | 服务端内存占用总计约 0.5G。 |
3.4 语言判定
在设计用户界面过程中,自动判定翻译方向可以简化用户操作。通过建立朴素贝叶斯分类器,可以比较准确地判断出源语言。该模型使用 Unicode“中日韩统一表意文字”U+4E00 到 U+9FCC 区段共 20941 个汉字作为识别文本的特征,并认为白话文和文言文出现概率相同。忽略 Unicode 中其他汉字区段是因为其中绝大部分汉字过于生僻,在实际文本中几乎不会出现。
训练语料采用前述白话文和文言文两个单一语言语料库。在训练模型时使用最大似然估计,并使用 Simple Good-Turing [13] 算法平滑数据,防止有零概率出现。计算之后将概率值取对数储存为 JSON 数据文件。
该模型的数据文件比较大,为了在网页客户端脚本中使用,将每个值量化,用 ASCII 中的可打印字符表示成字符串。计算时可直接取字符编码相加,比较结果。如果计算结果为零,则说明其中不包含模型中的汉字,无法确定翻译方向。
4 软件设计 [##]
4.1 软件结构
软件获得的用户输入为待翻译字符串和翻译方向。如果前端没有指定翻译方向,则在服务器端由上述朴素贝叶斯分类器进行自动选择。如果无法确定翻译方向,例如输入文本为其他语言,认为该文本无法翻译,所以按原样输出。之后服务端判断,如果用户短时间内请求太多,则生成验证码验证是否为人工操作;如果文本太长,则要求用户切分文本再提交,防止服务过载。
网页服务器将收到的文本通过 TCP 接口提交给后台翻译服务进程。该服务进程可以响应包括翻译、分词、简繁转换等命令,通过将这些服务集中在一个服务进程,可以提高稳定性,避免网页服务器重复加载词典。该服务进程同时管理两个后台 Moses 进程,分别负责两个方向的翻译。
在收到翻译请求后,先去除特殊字符,分行并按标点分句。其中在分句时,如果一句太长,则按逗号等标点切分,若还是太长,则直接按字数切分,防止一句翻译产生过多候选,占用内存过多或耗时过长。对于切分后的每一句话,检查是否包含上述“语言判定”中所使用区段范围内的汉字,如果没有则直接进入输出队列;将输入规范标点、统一转换为简体后,如果该句包含在缓存中,也直接输出。之后,程序为待翻译语句进行分词、XML 转义并在标点符号前后添加调序限制,通过标准输入调用 Moses 进程翻译。当 Moses 结束翻译,翻译服务进程解析其标准输出,XML 反向转义、解析词对齐,将结果加入输出队列,并加入缓存。最后,程序收集上述翻译结果,并按照调用参数格式化输出。网页服务器收到其回应后,按照用户浏览器设定中偏好的语言(简体或繁体) [♠♠] 转换输出文字,最后生成网页呈现给用户。
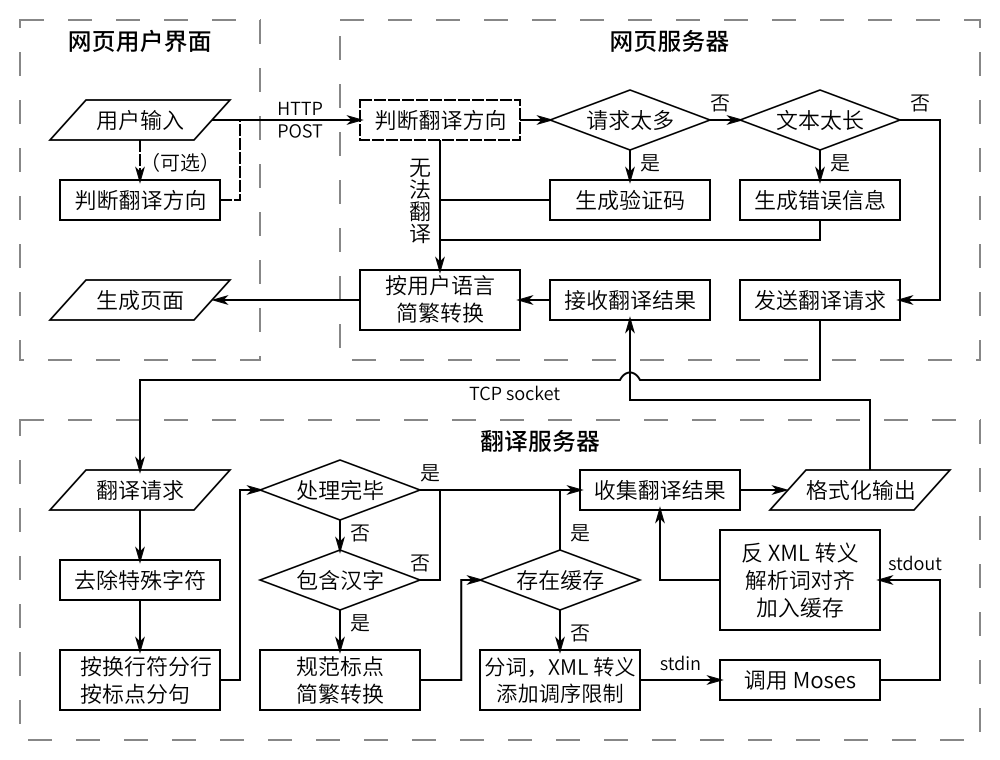
图 2 软件结构和翻译过程
在之后的开发中,该服务后端将实现翻译应用程序接口,从而实现即时翻译功能,并为相关开发者提供更简便的服务。
4.2 用户界面
本项目实现了基于网页的用户界面,使该文言文翻译系统成为一个网络服务。

图 3 基于网页的用户界面
该界面除实现了基本的输入、输出功能之外,还可以自动判别翻译方向,并可在结果中显示原文和译文中词语的对应关系。翻译方向的判别由上述语言判定模型完成,如果判定错误,用户可按“切换”按钮更正。鼠标移动,或触摸屏触摸到译文上的词汇时,在相应位置会高亮标出词汇的对应关系,用户从而能更好地评估翻译结果。在屏幕小的设备上,网页会自动适配为上下排版,方便用户操作。
| [##] | 「语言判定」部分以及该部分源码包含在 https://github.com/gumblex/pywebapps |
| [♠♠] | 即 Accept-Language 头。 |
5 相关研究对比
在网络上能找到的最早的文言文翻译软件是“文言之星” [♥♥],更新日期为 2001 年。该软件采用简单按照词汇表替换的方式进行翻译,且只能将文言文翻译为白话文。由于其边翻译边更新图形界面,所以速度较慢。[♦♦] 该软件翻译效果一般,没有考虑到分词和歧义问题,对上下文的处理能力较弱。 [♣♣]
在 2014 年 4 月百度翻译推出了文言文翻译功能 [***],能较好地完成文言文和白话文互译任务,对于未知文言文语句,其翻译结果会输出较多原文。通过本项目的几次失败实验,可以推测,百度翻译较本项目不足之处可能在于其模型为二元,或者在文言文分词方面有缺陷。百度翻译会对名句段进行直接匹配,而在匹配后再进行简繁转换,所以繁体和简体输入得到的结果可能略有不同。
例如:
- 孔子适郑,与弟子相失,孔子独立郭东门。(《史记・孔子世家》)
文言之星:孔你适郑,和弟你相失,孔你单独确定郭东门。
百度翻译:孔子到郑国,与学生相互失去,孔子独自站在郭东门。
本项目:孔子到了郑国,与弟子们失散了,孔子独自站在外城的东门。
- 少焉,月出于东山之上,徘徊于斗牛之间,白露横江,水光接天;纵一苇之所如,陵万顷之茫然。(《前赤壁赋》)
文言之星:少呢,月出在东山的向上,徘徊在争胜负牛的参与,白露横江,水光接天;纵一苇的处所象,陵很多一会儿茫然而。
百度翻译(原文为繁体):少了,月出于东山之上,徘徊在斗宿、牛宿之间,白露横江,水光和天际连结成一片;即使一苇之所如,陵万顷的茫然。
百度翻译(原文为简体):少了,月亮从东山的上空升起,在斗宿和牛宿两星座之间徘徊,白漾漾的雾气笼罩江面,水光和天际连结成一片;任凭苇叶似的小船飘向何处,陵万顷的茫然。
本项目:不多时,明月从东山后升起的上边,徘徊在斗星与牛的时候,白露横江,水光接上天;即使一叶小舟的地方,而去,李陵万顷的茫然。
可见上述例文均不同程度地出现在百度翻译和本项目的训练集中。文言之星完全缺乏合适的分词和歧义处理。百度翻译对名句的直接匹配可以在一定程度上弥补机器翻译的不足。本项目没有进行直接匹配,会尽量尝试进行翻译而不是直接输出难以确定的词组,并且能更好地反馈训练集的内容,即召回率较高。
使用相同的测试集、分词方法和 BLEU 算法对上述系统进行翻译质量评估,得到评分如下表。如表所示,本项目在翻译质量上能可见地超过上述研究。
| 系统 | 文言文到白话文 | 白话文到文言文 |
|---|---|---|
| 文言之星 | 6.12 | N/A |
| 百度翻译 | 20.41 | 34.11 |
| 本项目 | 30.48 | 48.19 |
本项目为独立项目,与上述研究完全无关。上述例文和评估数据均为测试当时所产生 [†††],会因各系统模型、参数或算法等更新而变化。
| [♥♥] | 自行搜索下载。 |
| [♦♦] | 17537 字测试集,文言之星用时约 51 分钟,百度翻译用时约半分钟(包括网络延迟),本项目用时约三分钟。 |
| [♣♣] | 在测试中采用了重新实现的 Python 版本以提高速度。 |
| [***] | 在「百度翻译」 网页或客户端中选择 |
| [†††] | 测试时使用的模型为 2016 年 3 月生成的模型,代号「陈振栋」。 |
6 结论与展望
本项目实现了一个基于统计模型的文言文机器翻译系统。该系统能对文言文和白话文进行较准确的互译,有比现有系统更高的翻译质量。本项目也实现了一个图形用户界面,方便用户进行翻译操作。本项目不仅使用了现有机器翻译框架,还针对文言文分词进行了优化、建立了用于识别文言文和现代文的模型并编写了整合功能较多、更适合中文的 Moses 前端服务,提供了一个新的文言文辅助阅读方法。
未来可以在这个基础上增添平行语料、加入词汇参数或句法模型,并改善语言模型,使翻译结果更精确;在翻译服务后端增加负载平衡等措施,提高翻译服务在云端部署的可扩展性。同时,用户界面可以加入即时翻译和字典等功能,使该系统能更适合于辅助文言文阅读和学习。由于本项目最终使用的模型文件总体大小较小,可以考虑进一步缩小模型文件并制作成手机应用,使用户在离线时也可以翻译文言文。 [‡‡‡]
| [‡‡‡] | 除非有资助或其他贡献者,这些展望很难实现。 |
7 参考文献
| [1] | Philipp Koehn, Hieu Hoang, Alexandra Birch, Chris Callison-Burch, Marcello Federico, Nicola Bertoldi, Brooke Cowan, Wade Shen, Christine Moran, Richard Zens, Chris Dyer, Ondrej Bojar, Alexandra Constantin, Evan Herbst, "Moses: Open Source Toolkit for Statistical Machine Translation", In Proceedings of the 45th Annual Meeting of the ACL on Interactive Poster and Demonstration Sessions, pages 177–180, 2007. |
| [2] | Philipp Koehn, Franz Josef Och, Daniel Marcu, "Statistical phrase-based translation", Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology, p.48-54, May 27-June 01, 2003, Edmonton, Canada |
| [3] | Rico Sennrich, Martin Volk, "MT-based Sentence Alignment for OCR-generated Parallel Texts". In Proceedings of AMTA 2010, Denver, Colorado, 2010 |
| [4] | Pi-Chuan Chang, Michel Galley and Christopher D. Manning, "Optimizing Chinese word segmentation for machine translation performance", Proceedings of the Third Workshop on Statistical Machine Translation, p.224-232, June 19-19, 2008, Columbus, Ohio |
| [5] | Kenneth Heafield, Ivan Pouzyrevsky, Jonathan H. Clark, and Philipp Koehn. "Scalable modified Kneser-Ney language model estimation". In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Sofia, Bulgaria, 4—9 August, 2013. |
| [6] | Kenneth Heafield, "KenLM: Faster and Smaller Language Model Queries." WMT at EMNLP, Edinburgh, Scotland, United Kingdom, 30—31 July, 2011. |
| [7] | Philipp Koehn, "An Experimental Management System.", Proceedings of the Machine Translation Marathon 2010, The Prague Bulletin of Mathematical Linguistics, vol. 94, pp. 86-96, 2010. |
| [8] | Chris Dyer, Victor Chahuneau, and Noah A. Smith. "A Simple, Fast, and Effective Reparameterization of IBM Model 2". In Proc. of NAACL, 2013. |
| [9] | Howard Johnson, Joel Martin, George Foster, and Roland Kuhn. "Improving translation quality by discarding most of the phrasetable". In Proceedings of EMNLP-CoNLL. 967–975. 2007. |
| [10] | Marcin Junczys-Dowmunt. "Phrasal Rank-Encoding: Exploiting Phrase Redundancy and Translational Relations for Phrase Table Compression", Proceedings of the Machine Translation Marathon 2012, The Prague Bulletin of Mathematical Linguistics, vol. 98, pp. 63-74, 2012. |
| [11] | Colin Cherry and George Foster, "Batch tuning strategies for statistical machine translation", In Proceedings of the 2012 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 427–436, 2012. |
| [12] | Papineni, Kishore, Salim Roukos, Todd Ward, and Wei-Jing Zhu. "BLEU: A Method for Automatic Evaluation of Machine Translation.", Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, pp. 311–318, 2002. |
| [13] | Gale, William A., and Geoffrey Sampson. "Good‐turing Frequency Estimation without Tears." Journal of Quantitative Linguistics 2.3 (1995): 217-37. |